Manual deployments of yesterdays
We, developers, are producing websites or applications for many years now. What kinds of tasks needs to be done, before we see the changes live on web. This was a big unknown to me for a very long time. Is my process of deploying the code the best practice? Should I do it other way? When I started creating websites, there was only one task and it was to deliver updated files to web server. I usually used the FTP client with nice GUI (graphical user interface). I logged in to IP address using login and password and copied files from left to right. :) Then I went to website, refreshed the page and checked that the changes are live. Simple, or not?
We used this approach in my very first job. I still remember the day, when I took down the website of my employer for first time. I made some new feature to the code. Marketing manager already sent out newsletter emails to customers and she was pushing me to deliver that feature that morning. It worked on my machine, so I decided to upload it to the live server with FTP client and I went straight for a brew to ease the stress. I have spent around 10 minutes drinking coffee in kitchen, looking outside the window (it was one of those nice sunny mornings in England). I was contemplating myself about my cool addition to the code and the genial way how I fixed the issue. I was also expecting thanking email from manager for delivering the feature on time. When I went back to office, the reality was “a bit” different. My colleague was on phone explaining to CEO, that we are aware of that issue and that the whole web dev team is looking into the issue as highest priority task. I sat to my computer and I realised it. The website was down! You know it, the error was typical white blank 500 page. In that time we didn’t even used version control system and my colleagues didn’t know that I have uploaded some updated files. They were wondering why has suddenly website gone down out from the blue. I have soon realised, that the problem was in my shiny new code. I fixed it fast and the website was up again. It was down altogether about 25 minutes. I’ve checked my emails only then. They were from managers, not even one was thanking me for the new feature. Also, my capability went down in eyes of my colleagues. That was the time before we used versioning systems or tests. The times I call ‘wild west’, where each cowboy shot first and asked questions later, where you didn’t have best practices and everybody made changes his own way. The times when chaos and uncertainty about code stability was a normal way of life.
Later I started to work for larger company on a bigger project where the release process was more complicated than just uploading few files with FTP. The release was complex thing and it had to be done each time the same way, without any error. Otherwise, the website would be down altogether with hundreds of clients surfing it at any time. I would again expect a not joyful call from my boss. The code consisted from several repositories which had to be cloned into certain folders and symlinked together in sub-folders, there were unit tests for each repository which had to pass in order to get to build stage. Even though in that time we weren’t using any package managers like composer or npm and we weren’t processing assets with gulp or similar tool, and we weren’t making DB update migrations, seeds or preprocessing images. It was still very complicated and I could see at least 10 places where it could go wrong.
What we want to achieve?
We can now see that the process of releasing the code to server can be more complex, than just simple FTP upload. We want to keep all changes in code repository - preferably GIT. We will automate the build, which means that we will run all tasks required in order to have working code and testing DB. Then we will run the self-testing, unit tests, behavioural tests or whatever tests we have. We will force developers to commit often, which reduce the number of conflicting changes to code and also is much easier to find errors in small commits. We will run CI after each commit. We need to run CI on develop branch too. That way we never merge failing branch to master branch. The testing environment should be very same to production environment (same version of OS, same version of DB server, same web server, same firewall settings, etc). Everyone should be able to see the results of builds - when it fails, what was broken and by whom. We will also receive an email when the status of repository changes to fail or when the failed build is fixed.
Selecting Strider CI
![]()
In this post I will be using an API code I’m currently working on. API is built in express framework on Node.js server and using mongoDB. There are many tools for Continuous Integration and I selected to use Strider, mainly because it:
- allows me to install it on my own testing server, which copies the production environment.
- it is open source software, check it out on github
- it is written in javascript, same as my code and running javascript code from it should be easy
- it runs on node.js, same as my code
- it is also Continuous Deployment platform
- you can code your own plugins and extend the functionality of Strider CI
Prerequisites
I assume you have the following:
- access to terminal on Unix server
- node.js
- mongoDB
- GIT
Installing and configuring Strider CI
- Install Strider
- Set up mongoDB
- Create initial admin user
- Running Strider
- Setting SMTP credentials
- Login and adding repository
- Selecting plugins
- Adding repository
- Setting up CI
1. Install Strider
Installation of Strider is quite straightforward, thanks to instructions on github. Install the Strider globally with:
npm install -g strider
alternatively you could get the code by cloning from git and installing all dependencies. I prefer this approach as I have more control of how it runs.
cd /var/www/
git clone https://github.com/Strider-CD/strider.git .
cd strider
npm install
2. Set up mongoDB
The CI uses mongoDB for storing users, invitations, repository information and so on. You can use locally installed mongoDB or use a remote one. The default values are set to use the local one and if you decide to use this, you don’t need to make changes in this step.
I decided to use remote mongoDB, so I can show you how to set it up. I have found mLab have sandbox plan, which offers a mongoDB with 500MB capacity for free. This is much more than our CI will ever need and therefore we will use it. Create an account and create a database as shown in screenshot. Select the free option and confirm that you agree to terms and conditions. mLab will create a mongoDB with name you want, I typed strider-foss.
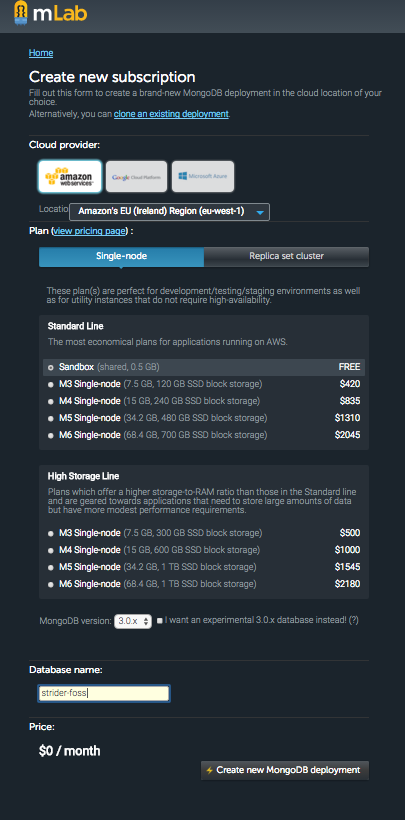
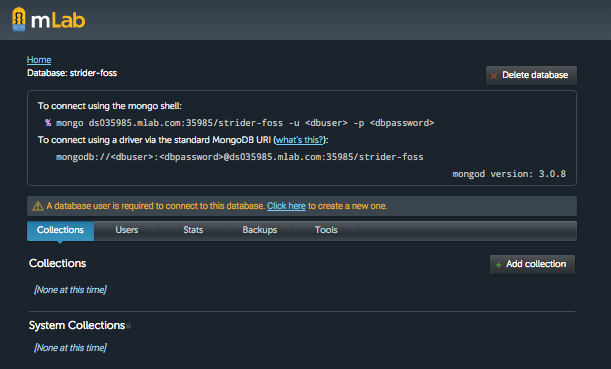
Now that you have database, check the url of db. We will need it to set up the Strider. You will also have to create a user and password to connect to this mongoDB, and it should be different from your mLab username and password.
Guys behind Strider prepared for us to use file called
.striderrc, which is basically a json configuration file. It is used by Strider when the node.js server is starting and
these configuration values can not be changed later at runtime. Lets create that file inside the Strider’s main folder:
nano .striderrc
now add our details of mongoDB in it. Your url will be slightly different from mine. Use the mongoDB user and password you created in mLab before.
{
"db_uri": "mongodb://dbuser:dbpassword@ds035985.mlab.com:35985/strider-foss"
}
3. Create initial admin user
You will have to create the initial admin user to be able to log in into the Strider. Luckily guys behind Strider thought about this, and they have created a simple script which guides you through steps and creates new user for you by simply typing:
node bin/strider addUser
Example:
$ node bin/strider addUser
Enter email []: strider@example.com
Is admin? (y/n) [n]: y
Enter password []: *******
Email: strider@example.com
Password: ****
isAdmin: true
OK? (y/n) [y]:
22 Oct 21:21:01 - info: Connecting to MongoDB URL: mongodb://ds035985.mlab.com:35985/strider-foss
22 Oct 21:21:01 - info: User added successfully! Enjoy.
You can see that Strider will use database strider-foss in mongoDB. That is the name of DB we have created in mLab.
4. Running Strider
Now you are ready to simply run the Strider with:
NODE_ENV=production npm start
If you open browser now and type in http://localhost:3000 or http://0.0.0.0:3000 you should see the strider login page, where you can log in with your new Strider admin credentials. That hostname and port are default for Strider.
However, the CI server I use is not located on my localhost. In fact, it is virtual machine in AWS cloud, and therefore I couldn’t see it in browser as it is set up now. I need to pass some parameters to node when starting strider. I can do these by exporting environment variables, something like the below before running strider:
export SERVER_NAME=strider.skey.uk:3000
The other option is to send the parameter altogether when starting the node.js:
NODE_ENV=production SERVER_NAME=strider.skey.uk:3000 npm start
Both options are not very optimal. We may forget to add variable when we start the Strider few days later and we may
end up investigating few hours what is wrong. I think the optimal solution is to store this configuration into
.striderrc file. So again, go to Strider’s main folder and open/create .striderrc with:
nano .striderrc
Now add server name and port on the end of json:
{
...
"server_name": "http://strider.skey.uk:3000",
"port": "3000",
}
Please note: In order to create subdomain with node.js, the DNS record for that domain must point to IP address of your server. If you don’t have domain name, you can use ip address as well.
Tip: I used for my Strider CI port 3000, because I have running Apache webserver on the very same server, which controls port 80. Therefore, I could not set port 80. What I could do in this situation is to set up virtual host in apache with subdomain strider.skey.uk and port 80. In virtual host setting I would set it to proxy to the port 3000 which is our node.js server running Strider CI. Then I could simply type in browser http://strider.skey.uk . I don’t know your server configuration, and so I don’t want to confuse you with unnecessary setting. I described creating virtual hosts in one of my previous blog posts.
Tip: AWS EC2 instances are usually preset with closed ports as it is the recommended practice. Because it is also our case, I had to log in to AWS console and open the outgoing TCP port 3000 for this instance to be able to use Strider on that port.
So now we can run the Strider with a simple node command, and it’s loading the correct configuration, but when we end the command, the Strider CI stops too. Not great, what we want, is to run the Strider as background service. We could use Upstart job on Ubuntu and create script that would daemonize Strider. That would be solution specific to one OS only. Instead, we want some more generic solution. We want be able to run on any operating system. The solution is pm2. Pm2 is advanced node process manager which allows us to run node instances as services, list them, monitor them and restart or stop easily. Firstly we will install it globally using npm
npm install pm2 -g
That’s it. Now that we have fully configured Strider, we can run it with pm2:
$ pm2 start bin/strider
[PM2] Starting bin/strider in fork_mode (1 instance)
[PM2] Done.
┌──────────┬────┬──────┬───────┬────────┬─────────┬────────┬─────────────┬──────────┐
│ App name │ id │ mode │ pid │ status │ restart │ uptime │ memory │ watching │
├──────────┼────┼──────┼───────┼────────┼─────────┼────────┼─────────────┼──────────┤
│ strider │ 0 │ fork │ 57541 │ online │ 0 │ 0s │ 7.711 MB │ disabled │
└──────────┴────┴──────┴───────┴────────┴─────────┴────────┴─────────────┴──────────┘
Use `pm2 show <id|name>` to get more details about an app
As you see, pm2 created an instance and tracks its status. You can list all running instances with pm2 list or you can
restart any node instance in case of configuration change with pm2 restart strider. You can also start more node.js
instances and pm2 will keep track of all of them.
5. Setting SMTP credentials
We will need to setup SMTP credentials to be able to send emails when CI tests pass or fail. Again, the choice is up to you:
- you may host your own smtp server
- use the SES from AWS
- use some other free service, such as
Mandrill(UPDATE: If I remember correctly Mandrill used to be free until - bought by Mailchimp)
In my case, I use SES from AWS. I had to validate email used for sending through SES and I created ticket requesting
300 emails per month. The customer service sorted out my ticket within hour, giving me free 50000 emails per day at
rate 14emails per second. That’s much more than Strider will ever use. To set up SMTP credentials you will have to open
.striderrc configuration file again and add your details at the end:
{
...
"smtp_host": "email-smtp.eu-west-1.amazonaws.com",
"smtp_port": "587",
"smtp_user": "<smtp_username>",
"smtp_pass": "<smtp_password>",
"smtp_from": "Strider CI noreply@skey.uk"
}
SES will provide you with username and password. After saving your settings, you have to restart the node.js running Strider to activate the changes. This time we use pm2 command:
pm2 restart strider
6. Login and adding repository
Now that we had setup everything required, we should open browser to your Strider instance http://strider.skey.uk:3000. You should see a login form with email and password. Use the admin account which we created before using strider’s script.
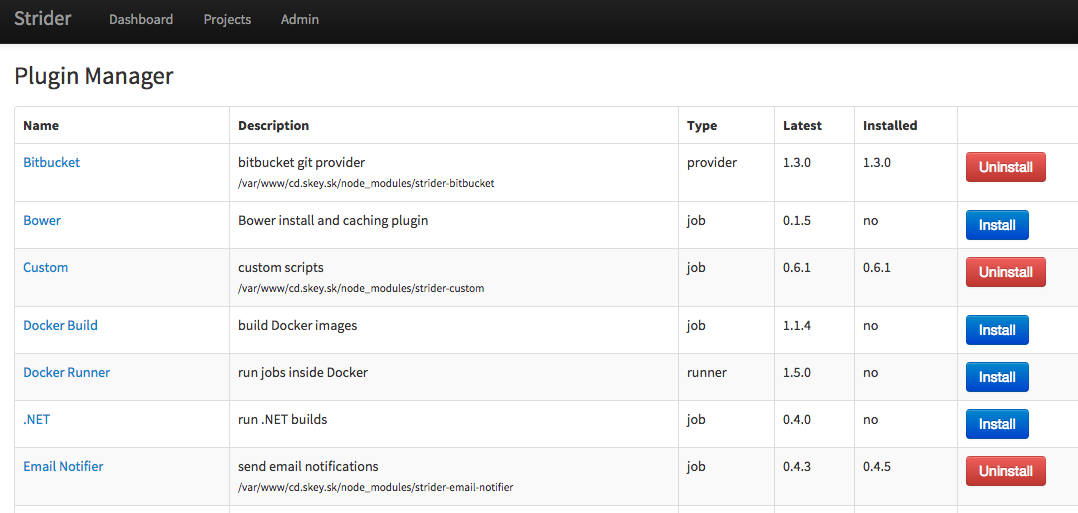
7. Selecting plugins
Go to plugins area in Admin menu and install or update the plugins which you want. The ones we will use is Custom Scripts and Email Notifier. You can add more plugins anytime to add more functionality.
8. Adding repository
Strider supports oAuth for GitHub and Bitbucket to connect it easily with your repository. However, if you have all the details, you can connect to any server with GIT repository. In my example, I connected Strider to bitbucket through oAuth. I also created a special user in bitbucket for Strider, towns-deployer, who has privileges to read repositories and create webhooks. Creating special bitbucket user for Strider is not necessary, but I have learned from past that managing special users for this type of task is better than changing permissions on your own bitbucket account. Strider has access to all repositories of deployer user account. This is thanks to oAuth authentication. You can see on screenshot, that Strider loaded list of all repositories, the user has access to and we can set up CI for each of those repositories.
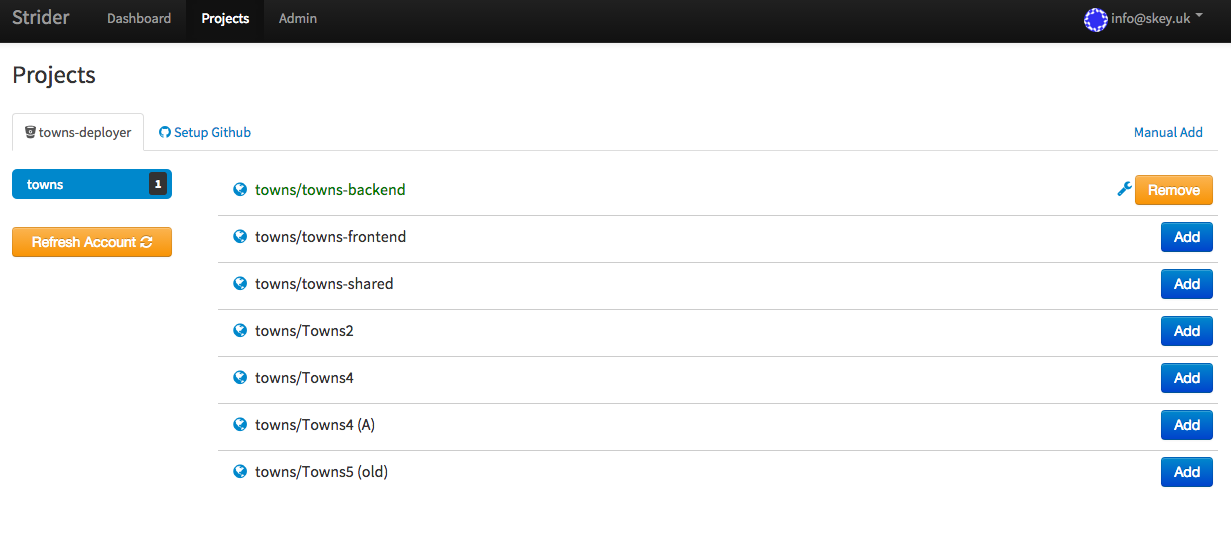
9. Setting up CI
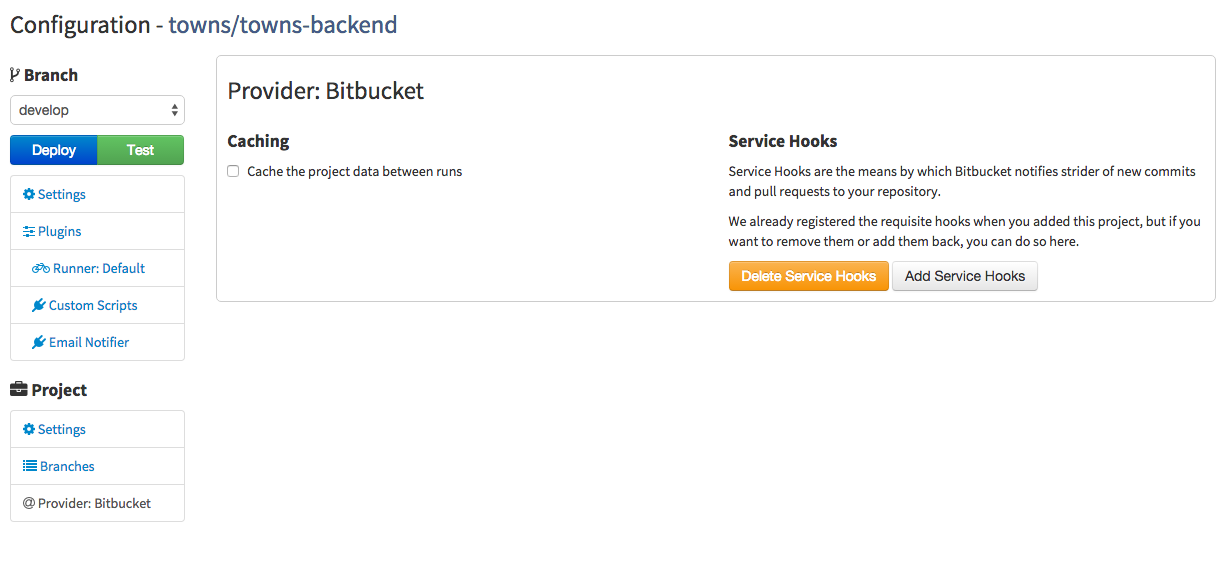
Select the repository you want to configure for CI. I don’t want to go into deep details on all options, because the interface is quite straightforward.
Service hook is simple record in git repository to make some HTTP request to url. This can be before commit,
after commit, after merge, etc. The URL of service hook is usually some API, which will trigger some action. In our case
the service hook will be triggered after commit and will call the Strider CI API, which will trigger the test. You will
want to setup service hook which is in last menu item Provider: Bitbucket. It will authorise bitbucket to touch url
in Strider’s API and that will automatically trigger CI for you. That means, that Strider’s CI will be triggered on each
commit or merge in bitbucket repository.
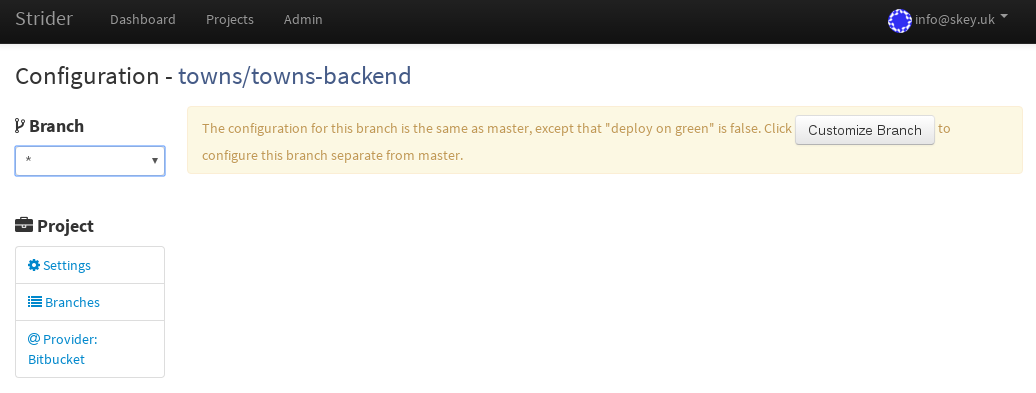
You can also set up branches on which you want to run CI. You can set different CI plugins and steps for each branch or you can have same setting as on master branch. I prefer having develop and master customized. Other branches doesn’t need to be tested for me, but you might be using different branching strategy. I want tests to be run on develop branch always, before I merge changes to live master branch.
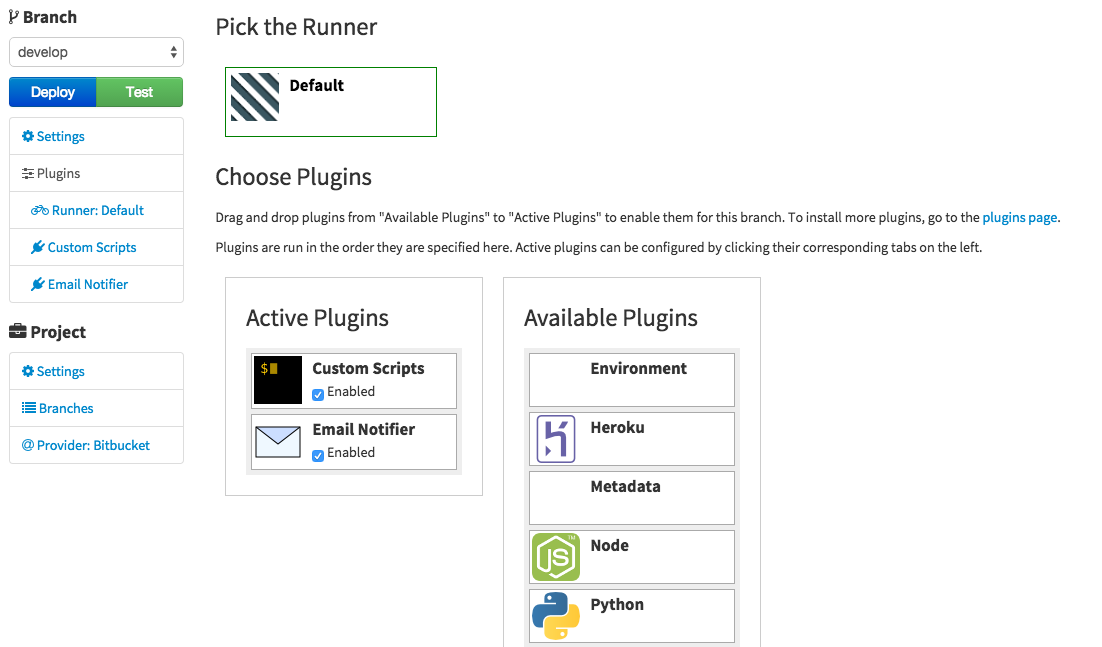
You can select plugins and their order on each customized branch. Therefore develop and master branch might have different test and deploy scenarios. Some of the plugins have some extra settings or fields to fill n and some of them don’t need any setup. As you can see on screenshot I added two plugins to runner and are displayed in left menu:
- The Custom Scripts
- The Email Notifier
Email Notifier will send us emails about results of the tests. The Custom Scripts is the most interesting and basically makes all the hard work. It is split into few parts, which are run in given order.
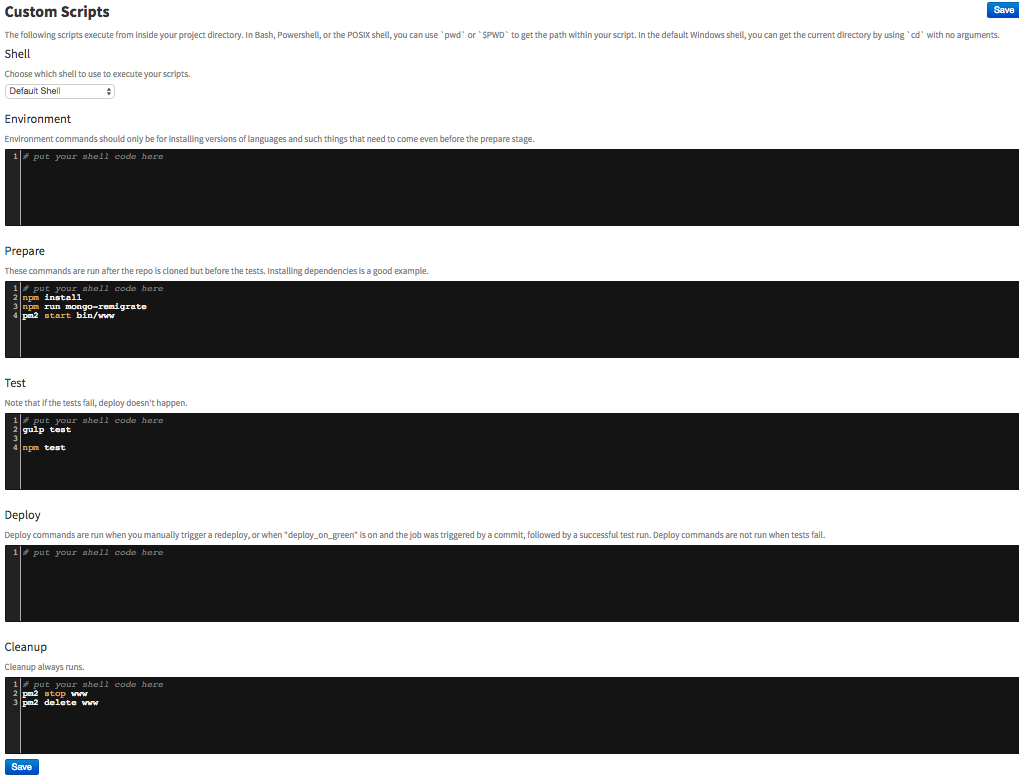
Continuous Integration Stages
Environment
Environment is a space where you can run some commands which prepares the server. You can here also install node or git or maybe just copy configuration file from some AWS S3 bucket. It’s up to you what you need to prepare, but in my case everything is ready for CI. The git repository is cloned out after Environment and before Prepare stages.
Prepare
Prepare is the stage where you are preparing the build, the git repository is already cloned out, and we can install npm dependencies, migrate DB entries into our DB and finally start node server with API from repository.
npm install
npm run mongo-remigrate
pm2 start bin/www
Test
Test is the most important part of CI. You can define here all commands which will run the tests. In my case I had simple javascript linter run through gulp. The second one is Mocha.js behavioural testing run by npm. You can add as many tests as you want. Just remember one rule: if any of these tests throws error, the next stage Deploy will not be run, and the build will be marked as failed. Also, please remember, that the code quality is only as good as is the quality of tests.
gulp test
npm test
Deploy
Deploy commands are run only when automatic tests pass or when you manually click “Deploy the build” button.
Cleanup
Cleanup will be run in any case at the end of testing or deploy. In my case, I’m just stopping the API node server to clean up resources and delete it from the pm2 list of instances.
pm2 stop www
pm2 delete www
After the test you will receive email about results of test. Therefore you don’t have to log in to Strider each time you commit to check the results.
Conclusion
At this point, you may want to create snapshot of your AWS instance, in case you would like to deploy more CI instances later. You now have a GUI tool set up to make CI. You can invite your coworkers, so that they will also see the state of current project and will be notified by email when anything goes wrong. You can also begin to explore other Strider’s features and plugins.
Strider is quite new tool and is still heavily developed as you can see on github. To update your Strider CI with new fixes of bugs, simply log into terminal and run as root:
npm update -g strider
In case you didn’t install Strider globally, you have to go to the folder with Strider and run:
npm update
PS: Thinking about the story I shared with you in the beginning of this blog post I now know few things for sure. Using this setup few years ago I would know that my hotfix would break the code and take down the website. I would also know it even before the changes would be merged to master branch. I would also be appreciated by my manager and my future would be much brighter. Please, do use CI for the brighter futures!