Continuous Deployment
In previous article Continuous Integration with Strider I demonstrated how to set up continuous Integration, that means how to test the code automatically and find out if it is the newest changes to code broke it or not. Now that you are automatically testing your commits, the next logical step in automation process would be to release our tested code to live website. We would want it to happen automatically, when all tests pass. We also want it to happen in short cycles, so no huge deployments will happen. If the code breaks, we will know it soon and exactly in which commit did it break. It is easier to spot one bug in one commit than investigate a bunch of bugs in twenty commits. This process is called continuous deployment. But wait, there is one more term called Continuous delivery. Let’s first look on the difference between them two.
What is the difference between Continuous Delivery and Continuous Deployment?
The Continuous Integration (CI) is just first 2 steps of putting code to production - building and testing code. When CI is done we may to chose how this code will get to production from one of 2 options:
-
In Continuous Delivery, when all tests pass, the build will be made and will wait, ready to be deployed. The last step, deploy of the code, will have to be done manually by some person, hence semi-automatic approach.
-
In Continuous Deployment the whole process from commit, through testing to deployment is automated. After all tests pass and build is ready, then the deployment pipeline will automatically deploy the code and update webservers to use it. This is fully automated cycle.
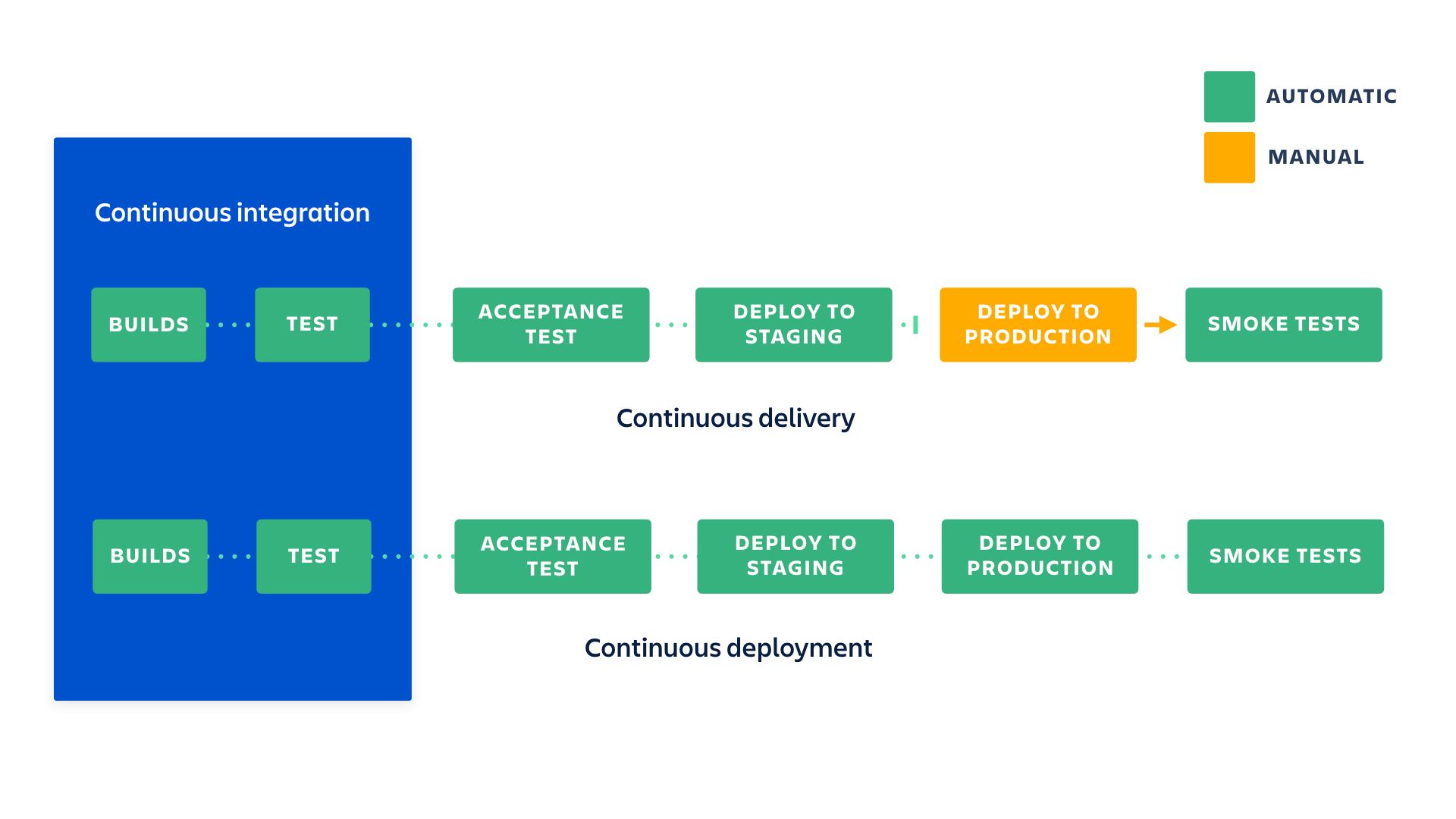
It’s hard to tell which one is better. Probably the best answer is: it depends on needs of your company/project. There might be companies which needs to wait until certain time to deploy new feature. While continuous deployment may not be right for every company, continuous delivery is an absolute requirement of DevOps practices. When you continuously deliver your code, you have confidence that your changes were tested and built properly and ready to deliver to your customers within seconds of pushing the “deploy” button. Actually once the Continuous Integration tool is set up, anyone with access to Continuous Integration tool can press deploy button when the business is ready for it.
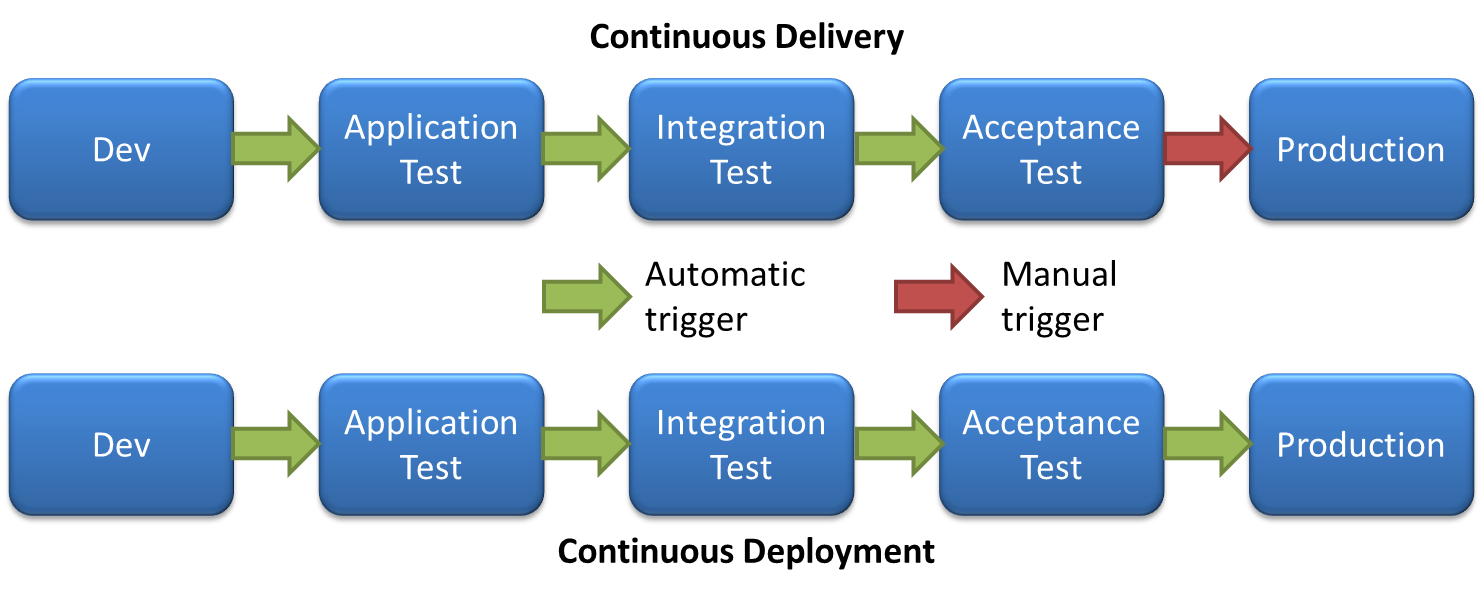
Steps to Continuous deployment with Strider
Let’s say that our application skey.uk has a brand new api and we want to deploy it to http://api.skey.uk/. That url will be our production api. We will set up this api such way, that it will be easy to set up another api (staging or testing). I split the process into the following six steps:
- Configure environment variables
- Create deployment script
- Start Api first time
- Setting up different branches
- Turn on continuous deployment
- Setup proxy for Apache Virtual Host
1. Configure environment variables
Sometimes you work with different environments: let’s say develop, test, staging and production. Each of them connects to different database with different credentials. Some of them may run on different hostnames or different ports. In the past, I used to have many if conditionals through my code, where I was checking IP address of server and based on it, I decided what environment it is. Or I was checking location of root folder of project or their combination. Trust me, that approach doesn’t work well and usually ends up as total mess. There are other options like exporting system variables, to which the server usually has access. That too didn’t work for me, mainly on shared hosting where I couldn’t set these up. Finally I started to use dotenv files. It is simple text file and looks like this:
|
|
It is the combination of keys and values, empty lines ignored, string values inside double quotes. Using dotenv package
mentioned above, you can easily access these values as variables in your node application. I usually add to git
repository only .env.example file for reference which is like placeholder with correct
keys. The file with real passwords is not part of git code. Thanks to this reference file i know, what values I need
to fill in. The only condition in code repository checks if the .env file is present, otherwise shows error page.
We will need to prepare such dotenv file for our production api. Let’s call it .env.production.
We need to fill correct values in this file, and we will store the file in safe place. It doesn’t matter where
we save it, unless it is not accessible by unauthorized people. I placed it into
/root/.strider/dotenv folder as this is default build directory for our CI. You probably
see the larger picture, that in case of setting up other servers, like staging one, you would place here .env.staging.
stefan@webserver:/stefan/.strider/dotenv stefan$ ls -la
total 16
drwxr-xr-x 2 root root 4096 Apr 1 16:31 .
drwxr-xr-x 5 root root 4096 Apr 1 16:31 ..
-rw-r--r-- 1 root root 188 Apr 1 16:30 .env.production
2. Create deployment script
You may have seen in Strider in last post that when I was defining Custom tasks, I left shell input field for Deploy empty. Commands in that field are run only when we are deploying code. We could write all commands straight in that field, but instead we will save those steps into shell file and store it in our code repository. Therefore, type in Deploy field:
# put your shell code here
bash ./bin/production-deploy.sh
As you can see, we are going to create production-deploy.sh file in folder bin in our
code repository . Again, the file name and folder name can be named to whatever. The .sh file extension means, that we
are going to write shell commands. Open the IDE of our choice, create that file in your code repository and add these
lines into file:
|
|
The line 1 says that the following will be bash shell commands. The line 3 will set the current date and time into
shell variable NOW. We will use this date to create folder name for current build. The line 5 will copy the content of
Present Working Directory ($PWD) to our deployment location. PWD will return us the directory where the strider builds
the code and if you didn’t specify it different in .striderrc file, then it will be /root/.strider/data/.
The line 7 will copy our dotenv file with production configuration from our safe place directly into our new build and will
also rename it from .env.production to .env. The line 8 will in my case run all new migrations and seeds. You may
not have to have this, but I do have to run it for my project.
The line 10 will remove current folder/symlink and line 11 will create a new symlink from new build directory to point to current directory. These two commands will happen in a few milliseconds. Effectively it’s atomic operation as nothing is copied, you just switch pointing from one directory to another.
Finally, the line 13 will restart the my-api node process, which will load node from new current files.
3. Start Api First time
First time is always a bit different,
your youth self may remember.
Stefan
There are some steps which needs to be done before automatic deployment script can be run.
- We will have to create deployment folder manually, otherwise the automatic deploy will fail to copy build:
stefan@webserver:~$ cd /var/www
stefan@webserver:/var/www$ mkdir api.skey.uk
stefan@webserver:/var/www$ cd api.skey.uk
stefan@webserver:/var/www/api.skey.uk$ mkdir current
stefan@webserver:/var/www/api.skey.uk$ ls -la
total 28
drwxr-xr-x 7 root root 4096 Apr 1 15:25 ./
drwxrwxrwx 28 root root 4096 Apr 1 15:25 ../
lrwxrwxrwx 1 root root 45 Apr 1 15:25 current
- Next, we will make first build and start the pm2 service, otherwise our command
pm2 restart my-apiin deployment script will not work. As you can see below, the first deploy steps are very similar to our deployment script. Your project may have a slightly different steps. What I’m doing here is cloning my git repository into current folder, then copying dotenv file, then running npm install and migrations and lastly starting pm2 server with name my-api:
stefan@webserver:/var/www/api.skey.uk$ NOW=$(date +"%F_%H%M%S")
stefan@webserver:/var/www/api.skey.uk$ git clone https://skecskes@bitbucket.org/skey/api.skey.uk.git ./current
stefan@webserver:/var/www/api.skey.uk$ cd current
stefan@webserver:/var/www/api.skey.uk/current$ cp /stefan/.strider/dotenv/.env.production /var/www/api.skey.uk/build-$NOW/.env
stefan@webserver:/var/www/api.skey.uk/current$ npm install
stefan@webserver:/var/www/api.skey.uk/current$ npm run mongo-migrate
stefan@webserver:/var/www/api.skey.uk/current$ pm2 start ./bin/www --name my-api
┌───────────┬────┬──────┬───────┬────────┬─────────┬────────┬─────────────┬──────────┐
│ App name │ id │ mode │ pid │ status │ restart │ uptime │ memory │ watching │
├───────────┼────┼──────┼───────┼────────┼─────────┼────────┼─────────────┼──────────┤
│ strider │ 0 │ fork │ 679 │ online │ 1 │ 24D │ 31.770 MB │ disabled │
│ my-api │ 1 │ fork │ 22730 │ online │ 0 │ 1s │ 04.699 MB │ disabled │
└───────────┴────┴──────┴───────┴────────┴─────────┴────────┴─────────────┴──────────┘
The following is an idea of how our deployment folder could look like after several deployments. That each build is in
a separate directory. There is only one current folder and that points to last build. The pm2 process with name my-api
was and is always called from current folder, so it loads correct configuration variables.
stefan@webserver:/var/www/api.skey.uk$ ls -la
total 28
drwxr-xr-x 7 root root 4096 Apr 1 23:36 ./
drwxrwxrwx 28 root root 4096 Apr 1 23:35 ../
drwxr-xr-x 14 root root 4096 Apr 2 09:12 build-2016-04-02_091230/
drwxr-xr-x 14 root root 4096 Apr 3 10:48 build-2016-04-03_104813/
drwxr-xr-x 14 root root 4096 Apr 4 14:33 build-2016-04-04_143320/
drwxr-xr-x 14 root root 4096 Apr 4 23:36 build-2016-04-04_233646/
lrwxrwxrwx 1 root root 45 Apr 4 23:36 current -> /var/www/api.skey.uk/build-2016-04-04_233646/
In case of some bug we can switch to previous build by creating symlink to previous build. We may also add some script which will check and delete old builds to save so some hard-disk space. We could also add some command to do database backup before deploy and upload the backup into AWS S3 storage. Basically you can shell script any functionality to this deployment script. This article shows you only basic steps to deploy.
4. Setting up different branches
Now you are ready with scripting and we can come back to Strider’s backend. We have to specify when will the deployment
happen. I assume that your git flow has some branches like master, develop or feature/make-this-work. Let’s also
say that master branch should always mirror what is in the live server, develop branch should be always on staging
server, and you just work on branch feature/make-this-work on your latest changes. The strider will currently run tests
and deploy after each commit.
Therefore, we have to specify what should happen after you push commits to individual branches. Open you project and click on branches menu item. You should see the page like on image below. Each of the branches can have separate steps on preparing build, testing or deploying. We will specify master, develop and *. Star is a wildcard for all other branch names.
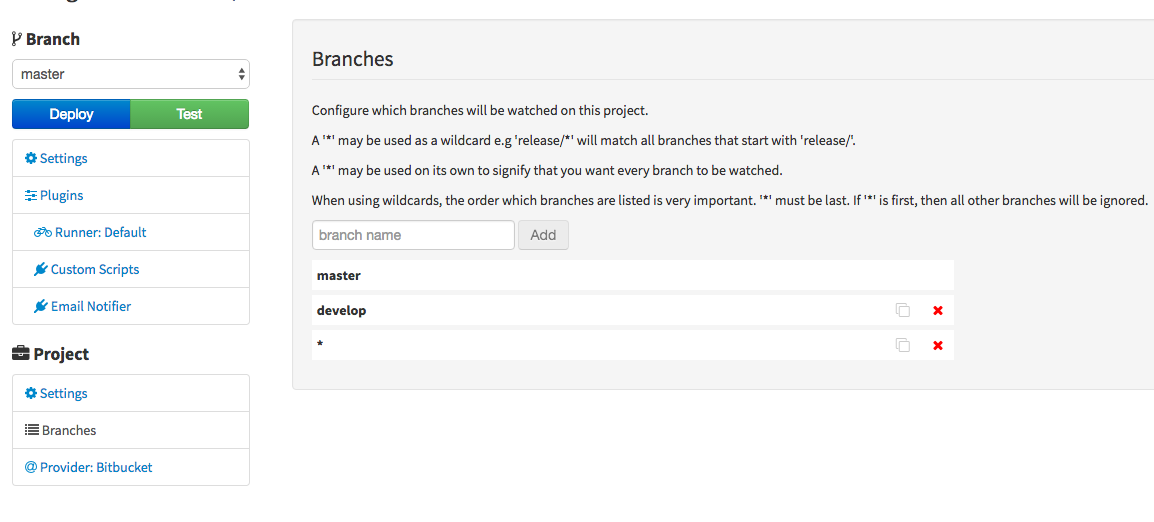
Now you can switch to different branches in menu from dropdown.
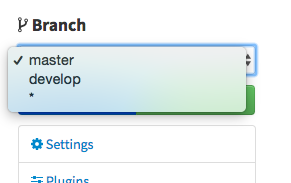
As you are switching from one to another, you will probably see the notice on screenshot below. Click on each Customize Branch button. We will customize each branch as we want Strider to do a slightly different thing with each of them.

5. Turn on continuous deployment
Now we can select each branch from the dropdown and set settings and plugins for it. Let’s select master branch first and go deeper into settings. Setting options offered here are:
-
Active - when ticked tests and deploys will happen automatically. We want to have this ticked on master branch and develop branch. Both branches should be stable to run tests and/or deploy to production/staging server. We probably don’t want it active on * as our /feature/make-this-work may be in development and may fail tests, we don’t want the whole team to receive email always when you commit to your feature branches. However, if you wish to run tests, you can do so manually. Each developer should be able to run his tests on his own environment even without Continuous Integration tool.
-
Deploy on green - means that it will deploy the code, when all tests pass. We will not tick it on * branches, just because we don’t want to deploy after commit to branch /feature/make-that-work. If we are deploying develop branch to some staging server, we may click it. If we are doing Continuous Deployment on production site, then we will definitively keep it ticket. But if we are doing Continuous Delivery then we will un-tick it, because we don’t want automatic deploy.
-
Deploy on Pull Request - In case you don’t have any tests, you can use this option to deploy the code after each commit. I wouldn’t ever do that without tests, but here you are the option in case you need it. We will not tick this in our examples.
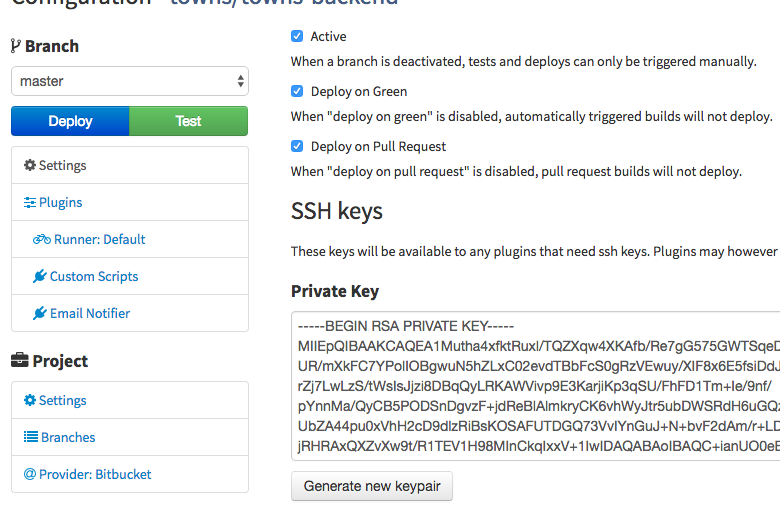
From left menu select Custom Scripts and check that Deploy shell area contains the
bash ./bin/production-deploy.sh command on master branch. Other branches shouldn’t have this and deploy field should
stay empty. In case you want to deploy to staging server, you will have to write another shell file which will be very
similar to this one, but will deploy to different folder and use different dotenv file.
Now you are in stage where you could see your first fruit from work so far. You can make your first deploy from Strider. You can do so by clicking on blue Deploy button or by pushing commit to master branch. If everything goes right, your tests turn green, you should see your new server deployed, up and running. Go to browser and type the url of your node project. In my case, I specified in dotenv file my project to run on localhost on port 3000, so I should type in browser http://localhost:3000 and the api index page should be there. If you specified different hostname or port, go ahead there.
Of course, if you are running it on your remote server or cloud, you will be not able to see it through localhost url. On my server I have running apache server which controls all connections to port 80. Therefore, I see these options here, on how to set it up:
- I can set hostname and port in dotenv file and use it (for example: api.skey.uk:3000/)
- I can set webserver like apache or nginx to proxy my node server to different url and port
6. Setup proxy for Apache Virtual Host
As you see I didn’t like the port and want a nice clean endpoint for my new API: http://api.skey.uk/ . If you want the same, don’t worry, because the solution is very simple. We will have to ssh into our server, go into apache configuration folder for virtual hosts and open the skey.uk.conf:
stefan@webserver:~# cd /etc/apache2/sites-available/
stefan@webserver:/etc/apache2/sites-available# nano skey.uk.conf
and add some lines, best on the top of the file:
<VirtualHost *:80>
ServerName api.skey.uk
ServerAdmin info@skey.uk
ProxyPass / http://localhost:3000/
ProxyPassReverse / http://localhost:3000/
</VirtualHost>
The above code will tell to apache webserver to listen on port 80 and if the requested server is api.skey.uk, then it will proxy it to localhost:3000, which is our new node api. Don’t forget to restart the apache web server to activate this new virtual host.
Open browser and type in http://api.skey.uk,(Ta-daaaa) well done.
Conclusion
We have set up Strider CD to make automatic Continuous Deployment. We also showed how to store passwords in dotenv file so the environment specific configuration details are not stored in code repository. We created script which will deploy our code. The script can do other tasks too, like backing up database, running some cron, or deleting old assets. Finally, we looked into Strider and set it up to use our deployment script and configured branches, so that each branch can do something else.
Happy Continuous Deploying!