Concurrency
Single-threaded, multi-threaded, concurrency, parallel tasks, async task… These words are used by programmers on daily basis and while most of us understands them (fingers crossed), I believe we are using this lingo in presence of non-technical people to confuse them? or to give them more detail, with little success. Let’s recapitulate what this all is, in very high level. So that next time my Product Owner or Scrum master understands what we talk about. Also, the described concepts are language agnostic, meaning that they are same across all programming languages and independently of operating systems.
Concurrency vs Parallelism
When we want do the tasks with CPU we must understand how units of work are being done and how can we scale them up or
speed them up. A CPU core can do one task at once, so we have learned few techniques over the years to squeeze more
power from the cpu. We often use terms like concurrency or parallelism and it is really important to understand
these concepts. Although they add some complexity, they make things happen faster. Let’s say we have 4 CPU Cores and we
want to describe approaches for following tasks:
- upload original image
- resize image
- upload resized image
- calculate checksum of original image
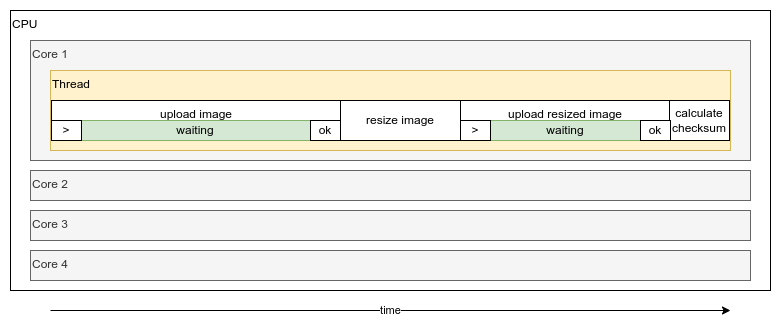
Without using concurrency or parallelism all these task would run in serial, one after each other, that is the least
ideal outcome, mainly for 2 reasons:
- we are not using other CPU cores
- while we are uploading images our CPU is not really doing anything, just waiting.
Parallelism
Parallelism is doing more than one thing at the same time. Therefore, our process will spawn more threads that can start to fight for CPU cores:
- Image upload will run in first thread will take first CPU core
- Image resize is run second thread will take second CPU core
- Image checksum is calculated in third thread will take third CPU core
- Resized image upload will run in fourth thread will take fourth CPU core
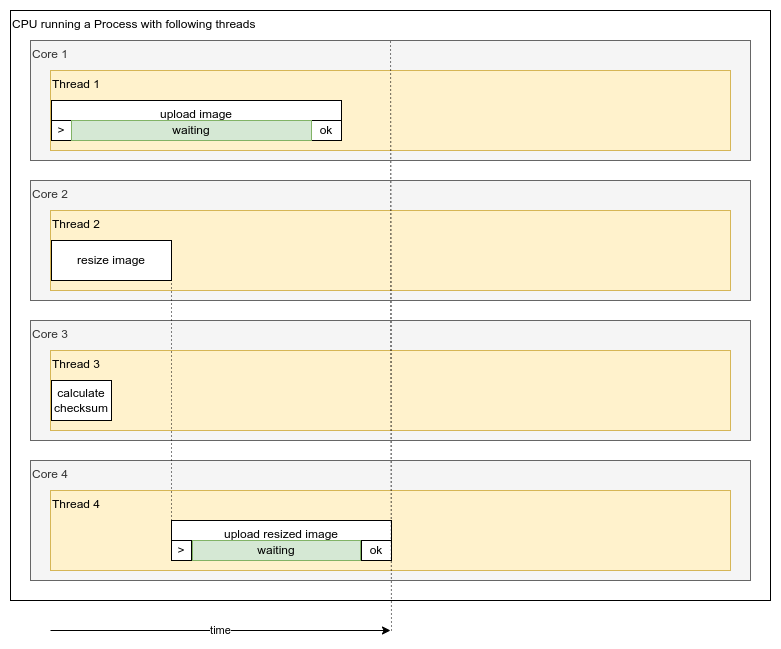
As we can see first three tasks could be done immediately and the fourth tasks was done as soon as the resized image was available. Multiple threads leveraged multiple CPU cores and most tasks were run in parallel.
Concurrency
Concurrency is providing an illusion of doing more than one thing at the same time as it all happens in one single thread using a single CPU core. In essence, it is switching between tasks while waiting for other task to finish.
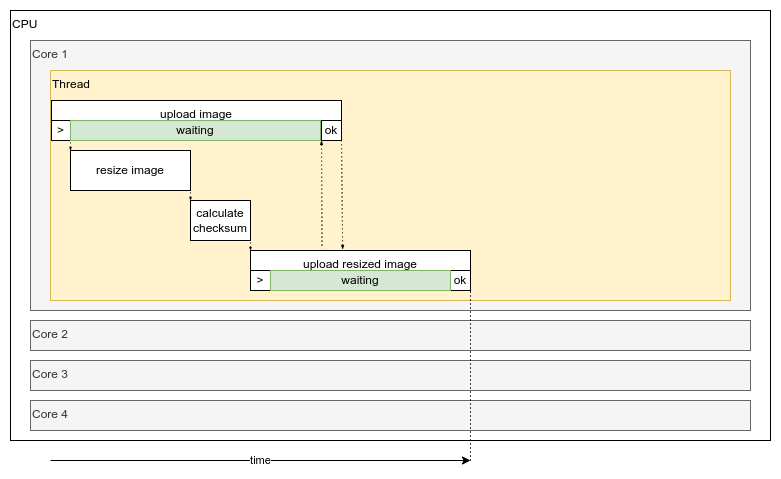
After the upload of original image started, there is not much needed from CPU, therefore instead of waiting, the thread will switch onto next tasks. Once the network transfers is also released the thread will start with upload of resized image. CPU is again waiting for the most of the resized file upload doing not much. The entire work was done on one CPU core in single thread and most of the tasks were asynchronous.
Processes
The CPU is processing instructions that comes from Processes. The Operating Systems (OS) is organising and maintaining Processes throughout their entire lifetime, gives them heap memory and controls access to CPU when process threads is requesting some tasks to be done.
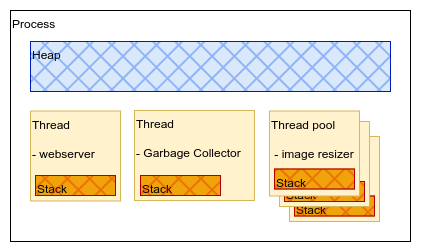
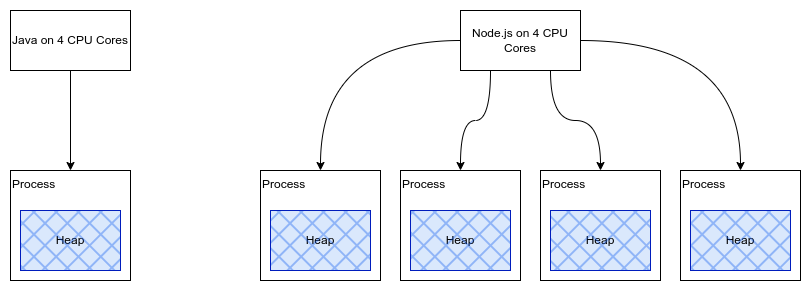
Each process has own memory space (called heap) and processes can’t read or manipulate other processes memory. Various languages are using processes differently. On a 4 CPU core system, Java will create a single process that can use all 4 cpu’s, while Node.js will create 4 processes to use all 4 CPUs. While both of them use all 4 cores, the difference is in memory space usage, because node.js will need 4 times more memory space for each of its processes. But generally, when we talk about the processes, we usually mean a single application or a command run from command line or a program that you just started.
Interprocess communication
While running a process with different threads we still want to be able to send messages between threads/processes,
to collect results, or to issue commands to threads and this is called interprocess communication (IPC).
There are 4 main ways how processes can communicate with each other. There might be some other ways to do this, but I
would call them hacking or edge cases, therefore I will focus only on 4 main IPCs.
1. Files
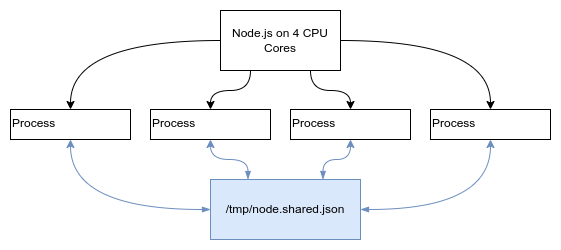
For example a node.js with 4 CPU cores running 4 processes can communicate using filesystem. Let’s say they store data in
/tmp/node.shared.json, then these processes can communicate through this file. Because writing into files is slow, we
could also use memory mapped file, but the data will be lost when the machine restarts. Not recommended, but doable!
2. Signals
Some signals are predefined, like 9 is kill process widely is used in terminal to send signal to process to kill it,
eg:
$ kill -9 5054
You can send some other signal to your process to signalize it something. The downside to this interprocess communication is that you are limited to one numeric signal code, and it needs to understand what to do with it (that means you need to implement what it should do with such signal code). This is pretty limited to what messages you can send, therefore not recommended either!
3. Pipes
An example would be running two processes with pipe, like when you want to list all files in folder and then you want to filter them to return only the ones that are json files:
$ ls | grep "json"
The standard output of first command becomes standard input of next command and the output from the second process will be written out in the terminal. While this is interprocess communication, you can’t usually send messages with pipe between 2 long-running processes, therefore it is useful mostly in simple shell scripts.
Pipe may be corrupted if accessed simultaneously by multiple processes. This is because pipe is not a file, but a communication mechanism between processes. It is not possible to seek to an arbitrary position in the pipe and therefore it is NOT thread safe.
4. Sockets
The best way for processes to communicate is by using sockets and there are three types, while you want one of these two:
-
Network socket - is for communication to the outside of server. For example webserver process can open socket 80 and allows you to communicate with that process through network.
-
Unix Domain Socket (UDS) - not limited to unix only, but are limited to the same machine. Also, these are much faster than network sockets. UDS come in 2 main types, stream-oriented sockets (similar to TCP) and datagram-oriented sockets (similar to UDP) and are leveraging system calls
sendmsg()andrecvmsg()
5. Queues
Queues are not really IPC, but they are used for interprocess communication. The idea is that you have a queue that is shared between processes, and you can push messages into the queue and pop messages from the queue. The queue can be stored in memory, or in filesystem or elsewhere as a linked list. The queue is thread and process safe, because it is implemented in a way that it can be accessed by multiple users at the same time.
Thread
Thread is what is executing your code and thread is run by process. For example javascript is called to be single-threaded, which is not exactly right, because it is running other threads to garbage collection, networking and so on, but only a single thread is available for application (that is code written by developer).
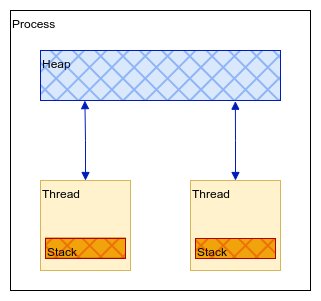
Each thread has its own memory called stack, for storing:
- local variables,
- method parameters
- calls chain
If you ever get error about Stack Overflow it is issue with your thread, that can’t go deeper in call stack, etc.
Otherwise, if you get out of memory exception that will be issue in process itself and is usually caused by creating
too many objects in heap memory or some kind of memory leak. Don’t forget that the heap memory is shared with all
threads in process and that is the most overlooked problem with multithreaded programs.
When Process wants to create a new thread, it needs to tell to operating system (OS) to create this for the process, and thus it makes spawning new threads relatively slow. So if you would like to build a webserver that will spawn a new thread for each request and then kill it after response was sent, it would probably be quite slow. Instead of spawning a thread per request, I would suggest to create a thread per function, like thread for image resizing and thread for image uploading, etc. The benefit of this approach is that you can create thread pools and limit your program to have only certain amount of threads that are resizing images in the same time. In addition, the OS is limiting the number of threads per process and how much memory it gets, to protect OS and other processes in the system, so that system remains stable.
Threads competes among themselves for shared resources inside process, like memory and CPU cores. For example if you
create 32 threads and have only 8 CPU cores, these threads will race for the CPU time. Similar with shared memory,
you will have to use Locks to control which thread can write to the shared memory to prevent threads overwriting shared
memory in same time. Or in best case use thread safe data structures.
For the above reasons, I would advise you to create programs that create threads that live for longer times and reuse them. Also, to prevent thread contention, create threads, but not many. I know this advice is vague, but it is about finding balance.
Conclusion
The table below summarises the differences between threads and processes in Python:
| threads | processes | |
|---|---|---|
| set-up cost | Low | High |
| Handled by | CPython Interpreter | OS |
| Memory Access | Shared | Separate memory spaces |
| Execution | Concurrent non-parallel | Concurrent parallel |
The above is not same for all languages, for example in Rust language, the threads are handled by the language itself,
not by OS, therefore the set-up cost is higher, but the memory access is also faster, because it is not handled by OS.
As previously described, it is not possible to single-handed-ly tell that one is better than the other one. There are many factors influencing when you get improvements by using these techniques, therefore it is much better if you understand when to use multi-threading and when multiprocessing in Python following this simple table:
| threading | multi-processing | |
|---|---|---|
| CPU limited tasks | use this | |
| CPU limited tasks with external libraries | use this | |
| I/O bound tasks | use this | |
| I/O bound tasks == CPU cores | either this | either this |
Generally, if you are doing CPU intensive tasks, you want to use multiprocessing, because you can leverage all CPU cores,
while if you are doing I/O bound tasks, you want to use multithreading, because you can leverage the fact that threads
are waiting for I/O and can switch to other threads. But this is not always true, because if you have 4 CPU cores and
you are doing 4 I/O bound tasks, you can use multiprocessing as well, because you will have 4 threads waiting for I/O
and 4 CPU cores to process other tasks. In addition, if you are doing CPU intensive tasks, but you are using some
external libraries that are written in C, you can use multithreading as well, because these libraries are using
GIL (Global Interpreter Lock) and therefore you can’t leverage all CPU cores anyway.
This article is preparation for future blog posts where I would like to go deeper into how variables and stored in heap
and stack memories and how borrowing and ownership works in Rust language. In any way, I hope we now have a better
understanding of how we processes can leverage threads and what types of memories we as developers have available.